基于 esp32 和水墨屏的二氧化碳浓度计
一个自带冗余备份的分布式文件系统
见 ArchLinux Wiki ,还有一个很常见的 Hadoop的DHFS
大概浏览了一下几个 DFS ,挑了一个文档比较全,源码也容易找到, (更重要的是,Arch源里打包了的) , MooseFS
MooseFS 分几个部分,分别是:
master :负责管理所有节点,可以有多个。需要较大内存metalogger :负责备份 master 的数据,在 master 挂掉的时候可以暂时代替其工作(如果你只部署了一个 master ,最好部署一个 metalogger )。尽量达到 master 节点配置需求chunk :数据保存服务器,数据就存在这儿。需要较大硬盘cgi :可以通过 web 查看整个集群的状态pacman -Sy moosefs
参考 安装指南
git clone https://github.com/moosefs/moosefs
cd moosefs
./linux_build.sh
make install
注意:我直接从 pacman 安装的,源码安装只在容器里编译安装过,并没有实际运行
首先,配置 mfsmaster :
在 /etc/hosts 中添加:
YOUR_MASTER_IP_1 mfsmaster
YOUR_MASTER_IP_2 mfsmaster
然后,将 /etc/mfs 下的所有 *.cfg.sample 改为 *.cfg ,大概是:
# 一行:
for f in /etc/mfs/*.sample; do mv -- "$f" "${f%.sample}" ;done
# 或者分开写:
for f in /etc/mfs/*.sample
do mv -- "$f" "${f%.sample}"
done
几个服务和对应的配置文件:
master : mfsmaster.cfg 和 mfsexports.cfgchunk : mfschunkserver.cfg 和 mfshdd.cfgmetalogger : mfsmetalogger.cfgmfsmount.cfg 、 mfstopology.cfg配置文件里全都有注释,如果使用默认,需要配的只有:
mfshdd.cfg在其中添加对应(虚拟)硬盘位置,没有挂载过的目录其实也可以,但是需要指定大小。详细配置请看 安装向导 的 Chunkservers Installation 部分。格式如下:
/mnt/mfschunks1 20GiB
在启动 master 之前需要先手动初始化一个文件:
cp /var/lib/mfs/metadata.mfs.empty /var/lib/mfs/metadata.mfs
启动所有节点后就可以在客户端进行 dfs 的挂载了:
mount -t moosefs ip:port:/ /mnt
向里面丢东西时速度会比较慢(取决于网速,如果你是千兆以上的网,当我没说)
mfsxxx -f start 可以让服务前台运行,就可以更清晰看到日志。 mfsmaster 还可以加 -xx 以查看详细日志,这对调试非常有帮助master 和 chunk ,会出现 这个问题 ,按回答的方法删掉相关文件就好goal 参数可以设置文件备份的次数,使用 mfssetgoal 和 mfsgetgoal 来查看和更改,也可以在 mfsexports.cfg 里添加挂载时参数 goal=x采用 docker ,每个模块编写一个 Dockerfile ,直接到指定机器上部署即可。其中 (最简单的) 一个 Dockerfile 如下:
FROM archlinux/base
MAINTAINER PinkD
# set mirrorlist and install moosefs
ADD mirrorlist /etc/pacman.d/mirrorlist
RUN pacman -Sy --noconfirm moosefs && rm -r /var/cache/ && rm -rf /var/lib/pacman/sync
EXPOSE 9425/tcp
#start service
CMD ["/usr/bin/mfscgiserv", "-f", "start"]
一个效率高的Android虚拟机,还支持arm
为啥不用avd呢?
那货速度虽然还不错,但是太耗内存和CPU,再加上AS和Chrome,直接内存爆炸
在官网下一个镜像,在VBox中安装。没错,就像安装Linux那样安装就行了,记得把system设置成rw,安装过程中会提示,重启过后就可以进入系统了
adb 连上,或者直接在内置终端里 su ,然后 which enable_nativebridge/data/local/tmp/ 下,然后 vi 它,在 wget $url 那句前添加 echo $v $url && exit ,运行它( /data/local/tmp 目录下),记下版本和地址,然后这个复制过来的脚本就可以删了。把文件手动从地址下载下来, adb push 进去,然后 cp /data/local/tmp/houdini.sfs /system/etc/houdini$v.sfs ,其中 $v 就是前面的版本,然后运行原脚本,就可以挂载兼容库。检查方法是看目录 /system/lib/arm 是否存在
用了一段时间,发现默认是横向布局,非常蛋疼,于是又想办法让它竖过来
16:9 算吧,然后设备内就 1080x1920 就好houdini 库只做了 armabi 的兼容, v7a 和 v8a 可能会炸chown 0:0
OpenVPN可以在 官网 直接下载
直接跟着安装程序的指引安装
如果你要多开,或者要使用多个需要 TAP 设备的软件(比如 TunSafe 和 tinc ),就可以使用 addtap.bat 和 deltapall.bat 来管理,其实就是使用 tapinstall.exe 命令安装和卸载设备,命令格式如下:
tapinstall.exe install OemVista.inf tap0901
tapinstall.exe remove tap0901
参考 官方教程
过程为:
注:
TAP 接口的名字,然后在配置文件中加上 dev-node dev_name 即可,这样指定接口可以防止多个使用 TAP 的程序互相冲突打开 OpenVPN GUI ,选择配置文件并启动即可
openvpn --config server.ovpn
也可以通过服务启动
到了这一步,OpenVPN启动完成了,也能连接上了,但是你会发现,连上了也上不了网,情况是包只能到服务器,但是不能从服务器出去,如果是在 Linux 上,直接 iptables -t nat -s xxx -j MASQUERADE 一把梭就搞定了,但是 win 不自带 NAT 配置,需要手动配置
服务器管理(Server Manager)->添加角色(Add Role)->网络策略和访问服务(Network Policy and Access Services)->远程访问服务和路由(Remote Access Service and Routing)
如果没有服务启用,先启用
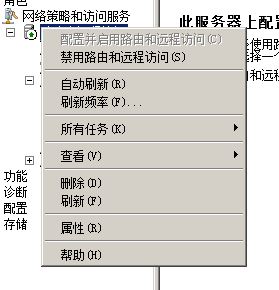
选择 NAT ,如果没有接口就添加,添加的对象为你的外网接口(本地连接)和OpenVPN的接口(本地连接 2)
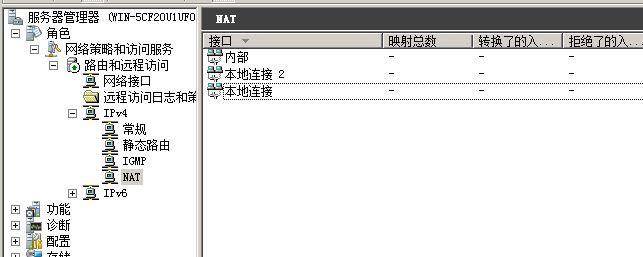
配置外网接口为公共接口,配置OpenVPN的接口为专用接口
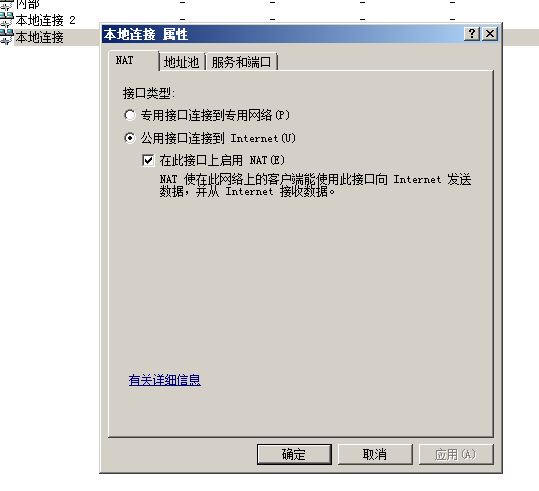
接口名可以在网络连接中查找(TAP)那个即为OpenVPN的接口
然后再在客户端试试,应该就能连网了
#垃圾windoge
一个服务端进程向操作系统申请一个 scoket 来监听,但是当进程退出后,还未关闭的连接不会立即消失,而是会留给操作系统处理。操作系统会尝试关闭这个连接。但是如果关闭时出现问题,这个连接就会一直处于 TIME_WAIT 或其他非正常状态,而这是相应的端口还处于占用状态,如果这个时候再重新启动这个服务端程序,就会出现地址被占用的情况
测试代码:
import socket
s = socket.socket()
s.bind(('0.0.0.0', 12345))
s.listen()
(client, addr) = s.accept()
print(client)
print(addr)
使用 nc 进行连接:
nc 127.0.0.1 12345
服务端会打印 client 和 addr ,然后正常退出,但是此时使用 netstat -anop | grep 12345 查看,发现对应连接并没有被立即释放
tcp 0 0 127.0.0.1:12345 127.0.0.1:59408 TIME_WAIT - timewait (28.18/0/0)
此时再次启动服务端,发现报错了:
Traceback (most recent call last):
File "server.py", line 5, in <module>
s.bind(('0.0.0.0', 12345))
OSError: [Errno 98] Address already in use
使用 setsockopt :
import socket
s = socket.socket()
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s.bind(('0.0.0.0', 12345))
s.listen()
(client, addr) = s.accept()
print(client)
print(addr)
此时就不会出现地址被占用的提示了
在 c 中也有一样的方法,只是方法声明不同, c 版的用法为
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(12345);
addr.sin_addr.s_addr = htonl(INADDR_ANY);
int s = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
int reuse = 1;
setsockopt(s, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse));
bind(s, (struct sockaddr *) &addr, sizeof(addr))
listen(s, )
struct sockaddr_in in_addr;
int len = sizeof(in_addr);
int client = accept(socket, (struct sockaddr *) in_addr, &len);
//handle client
//...
SO_REUSEADDR 之外还有一个 SO_REUSEPORT 的选项,查询后得知是 BSD 独有的, Linux 并不能用FIN 的问题,导致其立即关闭,因此客户端使用此选项时需注意接下来应该还有一篇关于 TCP 连接关闭的文章(咕咕咕
我使用的是高级版的 banana ,多了几个接口,功能更强大
foobar2000 和 PotPlayer ,且能输出到外设1.修改默认输入设备为软件提供的虚拟声卡( Voice Meeter 的话只有一个,其实是软件的虚拟输出)
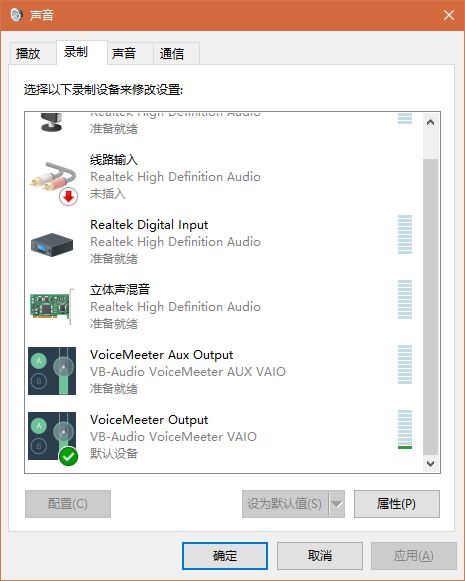
2.配置 Voice Meeter
引用官方的一张图:

HARDWARE INPUT 1 设为麦克风,将其输出的 A 取消, B 选中(输出到虚拟设备)HARDWARE INPUT 2 设为立体声混音器,将其输出的 A 选中, B 取消(输出到实体设备)VIRTUAL INPUT 1 输出的 A B 均选中(同时输出到虚拟和实体设备)HARDWARE OUTPUT A1 设为 MME 模式的扬声器( WDM 会冲突)3.配置 PotPlayer 或者 foobar
1.同上
2.修改默认输出设备为软件提供的虚拟声卡(软件的输入,注意不要与第3步中虚拟设备相同)
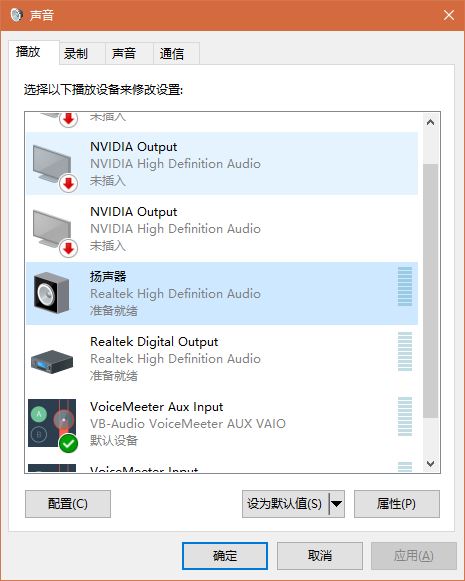
3.配置 Voice Meeter Banana
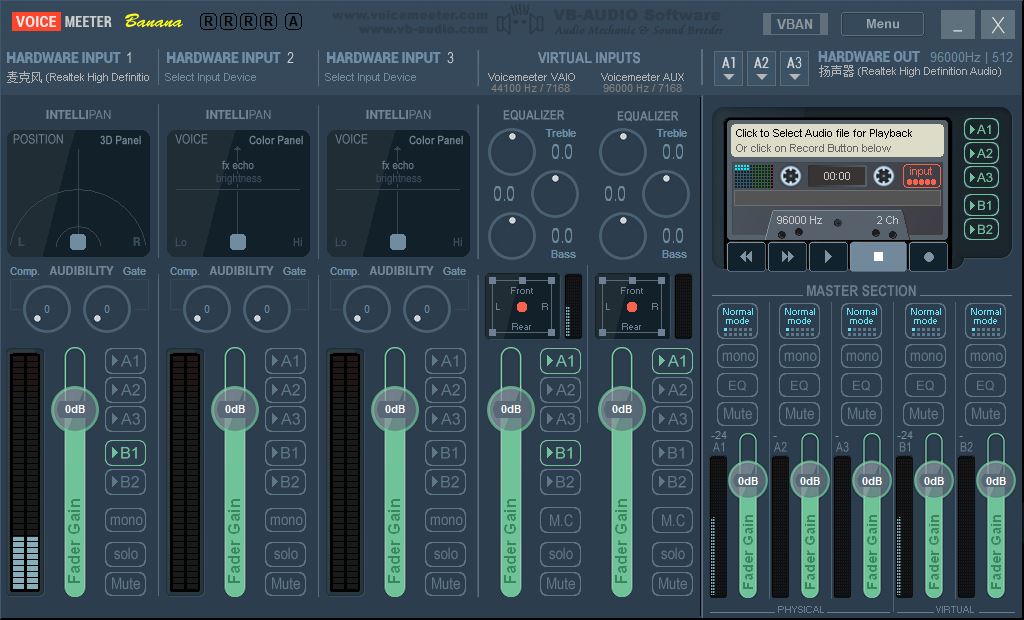
HARDWARE INPUT 1 设为麦克风,将其输出的 B1 选中(输出到虚拟设备1)VIRTUAL INPUT 1 输出的 A1 B1 均选中(同时输出到虚拟和实体设备1)VIRTUAL INPUT 2 输出的将其输出的 A1 选中(输出到实体设备1)HARDWARE OUTPUT A1 设为扬声器,不用担心冲突4.同上3
按理说因为设置了默认录音设备,所以直接使用即可,如果不能正常使用,请手动选择。有的软件不支持选择,又无法正常工作的(如 Telegram ),请重启软件再尝试
后面那几下就是我拍了几下麦的录进去的声音,前面是 foobar 播放的音乐
本机装着 ArchLinux ,突然想装双系统,玩儿游戏还是得用 Windoge
Win10 启动盘Linux 启动盘一定要有一个启动分区,剩下的自己看着整就好。
想装双系统的都会装单个系统->会装系统都知道怎么分区->看这篇博客的都知道怎么分区
如果你已经安装了某个系统,并且在分区的时候将整个硬盘都分了(我就是这样),那就需要调整分区大小了。 Win10 用系统自带的存储管理中的压缩卷功能就好, Linux 的方法看 如何在Linux中调整分区大小
Win10 就一路点就好,注意分区选择
先安装 ArchLinux 的情况下, Win10 会自动把启动文件( bootmgfw.efi )放到启动分区去,具体路径是 /boot/EFI/Microsoft/Boot/ ,而 grub 在 /boot/EFI/grub/ ,这些东西下一步会用到
如果你是开机时直接在 BIOS 选启动项的话,可以直接关掉这篇 blog 了
然而我做了 Secure Boot ,开了 BIOS 锁,每次进 BIOS 都需要输密码,很麻烦,干脆加到 grub ,统一管理
首先,在 /etc/grub.d/ 中添加(或修改)一个配置文件,让 grub-mkconfig 能将启动项写到 /boot/grub/grub.cfg 中。其实直接修改 40_custom 就好,自己添加需要注意文件名格式和 +x
添加的配置文件内容会被 grub-mkconfig 执行,把输出写到 /boot/grub/grub.cfg (没错,就是输出 stdout )。所以内容要可执行(然后 ArchLnux Wiki 上写的那个似乎就不可执行)。例如我新建的配置文件( 11_win10 )的内容:
# Win10
cat << EOF
menuentry 'Windows 10' {
echo 'Loading Windows 10...'
insmod part_gpt
insmod fat
insmod search_fs_uuid
insmod chain
search --fs-uuid --set=root --hint-bios=hd1,gpt1 --hint-efi=hd1,gpt1 --hint-baremetal=ahci1,gpt1 90C0-DEF4
chainloader /EFI/Microsoft/Boot/bootmgfw.efi
}
EOF
其中, search 行中的参数需要通过 grub-probe 获取,指令分别为:
grub-probe --target=fs_uuid /boot/EFI/Microsoft/Boot/bootmgfw.efi
grub-probe --target=hints_string /boot/EFI/Microsoft/Boot/bootmgfw.efi
就会得到 90C0-DEF4 和 --hint-bios=hd1,gpt1 --hint-efi=hd1,gpt1 --hint-baremetal=ahci1,gpt1
你可以把命令到脚本里,每次都会自动获取最新的参数,然而我直接写死了,反正一般来说不会变。
然后, grub-mkconfig -o /boot/grub/grub.cfg 。完了过后最好手动检查一下 /boot/grub/grub.cfg 中的内容是不是有你写的启动项
最后,重启,看看是不是成功了,没成功就找问题和解决问题吧
DLC什么鬼,这不是游戏啊魂淡
前面说到了,配置文件内容会被 grub-mkconfig 执行,把输出写到 /boot/grub/grub.cfg 。所以我后来还是决定写成脚本。然后, grub 的输出内容会在启动时从屏幕左上角开始输出(就像命令行)。于是,我有了个大胆的想法:在启动时用字符画一个 Windoge 。也可以画一个田字 (田牌操作系统)
配置文件如下:
# Win10
EFI_PATH='/EFI/Microsoft/Boot/bootmgfw.efi'
FULL_PATH='/boot'$EFI_PATH
UUID=$(grub-probe --target=fs_uuid $FULL_PATH)
HINTS=$(grub-probe --target=hints_string $FULL_PATH)
echo "menuentry 'Windows 10' {"
echo " insmod part_gpt"
echo " insmod fat"
echo " insmod search_fs_uuid"
echo " insmod chain"
echo " search --fs-uuid --set=root $HINTS $UUID"
echo " cat /grub/txt/test.txt"
echo " chainloader $EFI_PATH"
echo "}"
然后, test.txt
就可以在开机时看到 
因为突然想装双系统,本来把 Win10 装在机械硬盘的,实在是忍不了常年磁盘 100% 准备迁到 SSD 里(用的 DiskGenius 的分区备份还原功能,很棒)。然后现在 SSD 里已经装了 ArchLinux ,并且分区也是把空间分完了的,把分区整理好过后就准备开始调整分区大小。因为分区操作,所以有点方,就查了一堆资料,还在虚拟机做了实验,所以记录一下方法。不出意外下一篇是双系统的安装和对应 grub 的配置
Linux 的启动盘(需要包含 e2fsck , fdisk , resize2fs 等命令):已经挂载的分区没办法操作,所以需要在 LiveCD 里动手LiveCDlsblk 看看分区e2fsck -f /dev/sda1 检查需要调整的分区resize2fs /dev/sda1 100G 调整分区文件系统到 100G ,需要配合下一步才能生效fdisk /dev/sda ,进去删掉( d ) sda1 ,然后再新建( n ),除了结束大小,其他全部默认就好,结束大小应该写 +100G ,保留 EXT4 签名那个我选的 N ,两个都试过,似乎没什么影响e2fsck -f /dev/sda1 检查一下,没有错误就说明没问题了然后,你就可以在腾出来的空间里装 Windoge 了
算是划水+笔记吧
Microsoft 上是这样说的:
Secure Boot is a security standard developed by members of the PC industry to help make sure that your PC boots using only software that is trusted by the PC manufacturer.
When the PC starts, the firmware checks the signature of each piece of boot software, including firmware drivers (Option ROMs) and the operating system. If the signatures are good, the PC boots, and the firmware gives control to the operating system.
SecureBoot 在你系统启动前会对内核等底层的东西进行签名验证。验证通过则继续启动,验证失败无法进去系统并弹出提示。
当你的内核遭到修改(被植入后门什么的)时, SecureBoot 会阻止系统启动,这样就能防止那些图谋不轨的人进入系统。
49:配合全盘加密食用,味道更佳。
UEFI (可扩展固件接口)负责加电自检、联系操作系统以及提供连接操作系统与硬件的接口 [wikipedia] 。说白了就是用来替代BIOS的。具体参考 Wikipedia
据说因为巨硬给 EFI 做出了不少的贡献,所以 EFI 的文件格式是 PE 而不是 ELF 。而且最开始的部分电脑只能使用厂商内置的key和微软的key进行签名,导致Linux下根本无法配置 SecureBoot 。阮一峰有提到过
!!请确保你的 BIOS 支持 SecureBoot 中的自定义密钥选项!! ,不支持我也没办法。
没错,代码都是复制粘贴的
openssl genrsa -out test-key.rsa 2048
openssl req -new -x509 -sha256 -subj '/CN=test-key' -key test-key.rsa -out test-cert.pem
openssl x509 -in test-cert.pem -inform PEM -out test-cert.der -outform DER
你也可以使用你自己的RSA私钥生成一个key。用rsa的key登录ssh的人应该都知道怎么生成吧(然而并不。不知道就搜呗,就像我)
sbsign --key test-key.rsa --cert test-cert.pem --output grubx64.efi /boot/efi/efi/ubuntu/grubx64.efi
cp /boot/efi/efi/ubuntu/grubx64.efi{,.bak}
cp grubx64.efi /boot/efi/efi/ubuntu/
目录什么的需要自己改成自己的。更改 /boot/ 下的文件需要 root 权限,记得 sudo 。以上命令也可以对内核文件使用。
每次更新内核都要手动签名会累死的。在 ArchLinux 里面直接可以添加 hook ,具体看 这里 。将写好的 hook 放到 /etc/pacman.d/hooks/ 即可。 Ubuntu 下参考 /etc/apt/apt.conf.d/ 目录下的配置(并没有具体尝试)。 Pacman 的配置如下:
[Trigger]
Type = Package
Target = linux-xxx # your kernel package name
Operation = Install
Operation = Upgrade
[Action]
Description = Secure Boot Sign
When = PostTransaction
Exec = # sign your vmlinuz here
Depends = sbsigntools
签名操作不能对 initramfs 进行签名,因此需要将 initramfs 和内核文件 vmlinuz 打包在一起一并签名。然而我并没有做这一步,过程可以在 这儿 找到。这篇文章写得很详细(但是太TMD折腾了,所以搞到上一步就没搞了)。
配置完 SecureBoot 记得给 BIOS 加密码,不然人家直接改启动,开了 SecureBoot 也白搭。
10.8.8.0/24主要参考 海运的博客 和 qiuske的ChinaUnix博客 。文中是针对两个接口,多个的话自己手动改一下即可
首先, MASQUERADE openvpn的网段:
iptables -t nat -A POSTROUTING -s 10.8.8.0/24 -j MASQUERADE
这是iptables最基础的应用,详情请自己搜索关键词 iptables MASQUERADE
然后,给每条连接打上 CONNMARK :
iptables -t mangle -A PREROUTING -s 10.8.8.0/24 -m state --state NEW -m statistic --mode nth --every 2 --packet 0 -j CONNMARK --set-mark 1
iptables -t mangle -A PREROUTING -s 10.8.8.0/24 -m state --state NEW -m statistic --mode nth --every 2 --packet 1 -j CONNMARK --set-mark 2
解释一下:
mangle 表在 nat 表之前生效-m state --state NEW —-> 匹配新建的连接-m statistic --mode nth --every n --packet x —-> 统计,每n个包,对第x个进行匹配-j CONNMARK --set-mark x —-> 交给 CONNMARK 处理,打上标记 xCONNMARK 打上的标记是针对连接的,由iptables管理的,因此,还需要将标记打到每个包将连接上的标记打到每个包上:
iptables -t mangle -A PREROUTING -m connmark --mark 1 -j CONNMARK --restore-mark
iptables -t mangle -A PREROUTING -m connmark --mark 2 -j CONNMARK --restore-mark
解释:
-m connmark --mark x —-> 对于 CONNMARK 标记为x的-j CONNMARK --restore-mark —-> 将连接的标记打到包上参考 海运的博客 和 iptables-extensions的文档
ip route add 10.8.8.0/24 dev tun0 table p0
ip route add default dev ppp0 table p0
ip route add 10.8.8.0/24 dev tun0 table p1
ip route add default dev ppp1 table p1
ip rule add fwmark 1 table p0
ip rule add fwmark 2 table p1
说明:
/etc/iproute2/rt_tables 中指定的名字fwmark 即为之前打在包上的标记,按照这个标记来走路由,就能实现按连接的负载均衡traceroute 能到 pppx 的路由地址,但是接下来的包全都在服务器端,并没有发回 openvpn 的客户端(抓包发现的)nc -vv -l -p 23333 ,客户端 nc -vv x.x.x.x 23333 ,外网服务器端通过 netstat 可以看到连接的状态是 SYN_RECV 。也就是说,三次握手,第一个包收到了,发出了第二个包,在等待第三个包,然而这第二个包看起来并没有被客户端收到MASQUERADE 分解开来,改成 SNAT + DNAT 发现 SNAT 有包被匹配到,而 DNAT 几乎没有这种方法比较古老了,效率也不高,但是思路是没有问题的,因此依旧想将这个方法实现。如果有大佬发现问题出在哪里欢迎联系
就一句话:
ip route add default nexthop dev ppp0 weight 1 nexthop dev ppp1 weight 1
说明:
nexhop 指定下一跳dev 指定接口weight 指定权重,全1就好当然,别忘了
iptables -t nat -A POSTROUTING -s 10.8.8.0/24 -j MASQUERADE
BTW,遇到已经存在默认路由的,删掉就好
说明:
pppoe 下不用指定 via 参数,因为 pppoe 本身就是点对点,不像以太网那样靠广播,需要手动指定网关。这个知识点来自49师傅和另外一位不愿意透露联系方式的大佬(大雾)
注:此文章中线程不特殊声明,均为Android主线程。
Force Close ,就是程序发生了未被捕捉的异常,也称 FATAL EXCEPTION ,导致程序崩溃,并弹出 令人愉快的 Unfortunately (雾) 。
UncaughtExceptionHandler 处理在 UncaughtExceptionHandler 中写好就可以了。
因为在主线程崩溃后,Android的消息机制已经炸了,默认的 UncaughtExceptionHandler 就是并关闭程序弹出 令人愉快的 Unfortunately。可以选择在处理完成后重新启动App。例:
Thread.setDefaultUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
//LogUtils.save(e);
//具体方法网上一大堆,还可以打印机型、系统版本等信息
Log.e(TAG, "uncaughtException on " + t.toString() + ": ", e);
//重启App
context.startActivity(new Intent(context, BootActivity.class).addFlags(Intent.FLAG_ACTIVITY_NEW_TASK | Intent.FLAG_ACTIVITY_CLEAR_TASK));
System.exit(-1);
}
});
这个问题是我没想到的,因为崩溃都发生了,一般的想法就是安排后事,而不是继续 续 。
在此感谢 AndroidDevCN 中的 Aesean
在主线程崩溃后,Android的消息机制已经炸了,但是我们有没有办法 续 一发呢?
了解Android消息机制的都知道(不了解的网上搜一搜吧,这儿 也有一篇blog),Android的主线程就执行了几行代码,大概就是:
public static void main(String[] args) {
Looper.prepare();
initMessageQueue();
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
//加一句测试代码
System.out.println("喵喵喵?");
}
而 UncaughtExceptionHandler 就是在当前线程异常发生时跳转到其中的代码继续执行,然后就退出线程。所以, System.out.println("喵喵喵?"); 并不会执行。 注意,在执行完 UncaughtExceptionHandler 之前线程并没有死。第一段代码中的 t.toString() 的 t 就是主线程。
那么,问题来了,该如何防止崩溃呢?
既然线程发生异常,消息队列被破坏,那我们让消息队列继续运行不就可以实现 续 的目的了?所以,可以这样写:
Thread.setDefaultUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
Log.e("TAG", "uncaughtException: ", e);
Looper.loop();
}
});
但是问题又来了,这样只能防止第一次崩溃,第二次依旧会导致程序出现问题。
这就是 Cockroach 这个库所做的。思路很巧妙。
主要源码就是 Cockroach.java 。
大概分析一下:
Thread.setDefaultUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
Log.e("APP", "uncaughtException: ", e);
while (true) {
try {
Looper.loop();
} catch (Exception e1) {
Log.e("APP", "uncaughtException: ", e1);
}
}
}
});
就是向 UncaughtExceptionHandler 添加一个死循环,这个死循环又调用 Looper.looper() 来获取 MessageQueue 中的 Message 进行处理,发生异常就处理,然后继续执行 Looper.looper() 。这样消息循环就不会被破坏,线程也不会退出,就可以做到 无限续 的作用。
在 Cockroach 中还做了一些优化处理,详见源码。
然而有些异常依旧会导致 FC ,比如JNI的异常。所以这个方法也不是万能的,只是一种抢救和优化的方案。
对了,今天似乎是虵的生日
源程序:
#include <stdio.h>
int main() {
int x = 1;
x += x++;
printf("%d\n", x);
return 0;
}
程序运行结果:3
gcc test.c,拖入IDA进行分析。
汇编代码:
mov [esp+20h+var_4], 1
mov eax, [esp+20h+var_4]
lea edx, [eax+1]
mov [esp+20h+var_4], edx
add [esp+20h+var_4], eax
mov eax, [esp+20h+var_4]
mov [esp+20h+var_1C], eax
mov [esp+20h+Format], offset Format ; "%d\n"
call _printf
leave
retn
分析:
(esp+20h+var_4) 即为x
x置1
eax存x的备份
将edx置为eax + 1(即为2,x++的结果)
将edx放回x
x += eax
将x送入eax进行输出
所以x += x++就变成了:
x1 = x++;
x += x1;
即先做了 x++ 操作,返回了1,然后再进行 x += 1 操作。
为什么会这样呢?
因为运算符优先级中, ++ 远大于 += 。
public class test {
public static void main(String[] args) {
int x = 1;
x += x++;
}
}
程序运行结果:2
javac test.java 然后 javap -c test
汇编代码:
0: iconst_1
1: istore_1
2: iload_1
3: iload_1
4: iinc 1, 1
7: iadd
8: istore_1
9: return
分析:
因此,x++的结果并没有被使用。
值得一提的是,在IDEA中,代码会有以下提示:
The value changed at 'x++' is never used
可见,一个优秀的IDE对于程序猿来说是很有必要的。
最后,感谢一下某学员
分析这个问题之前,我们应该先了解一下RecyclerView的工作原理。
官方文档中是这样写的
用图片来说明一下大概原理:
原理解释:RecyclerView会创建比屏幕上可见数量多几个的ItemView用来显示Adapter中的数据。在用户上下滑动时,RecyclerView会自动回收处理那些不可见的ItemView,以方便重复使用,减小各种资源消耗。
那么,为什么会出现所谓的图片加载乱序问题呢?
网络加载图片的基本流程是这样的:
InputStream,用BitmapFactory.decodeStream解析为BitmapImageView.post方法(或者其它方法)来更新UI问题出在哪儿呢?
举一个最容易理解的例子:
假设ItemView1中的ImageView先进行网络请求,然后用户快速滑动,ItemView1被回收了,但是图片加载方法中还在继续加载图片。然后用户继续滑动,ItemView1重用了,再一次进行网络请求。如果此时第一次请求时网络卡了(或者其他的什么原因),造成第二次先请求完成,就会出现第二次请求先更改ImageView内容为Image2,然后第一次请求又将其更改为Image1的情况,这样就造成了图片乱序。
ImageView中有一个Tag属性。我们可以从这个属性入手,找到解决方法。
具体思路:
ImageView.setTag方法将tag设置为图片来源(一般为url)ImageView.post前附加判断url.equals(imageView.getTag()),如果不等,就说明已经有新的图片正在加载了,于是跳过更新图片操作